OkHttp源码解析-(下)
文章目录
这篇的主要内容就是解析这一个个拦截器,所以重新将图放在这里。
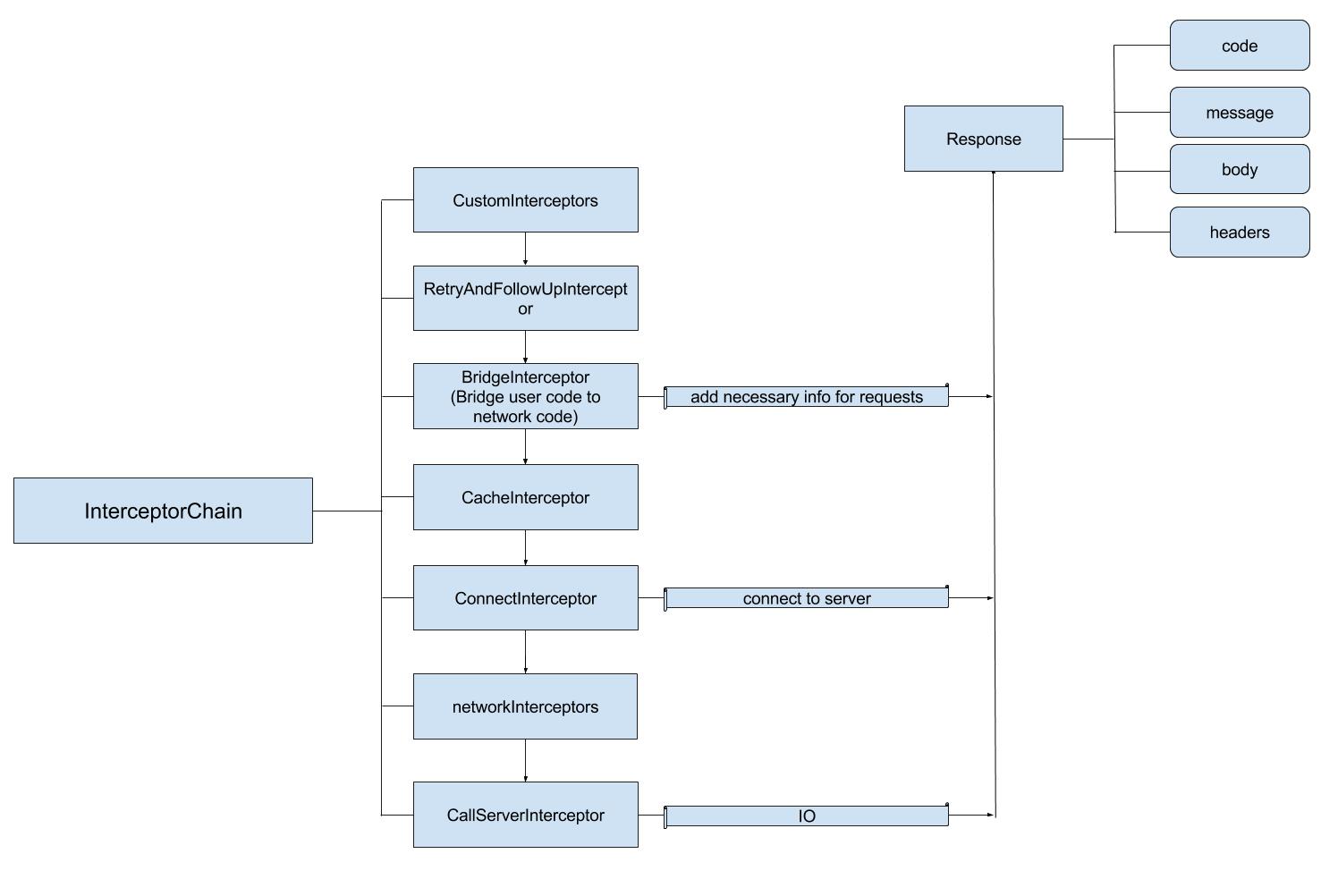
图中存在用户自定义的Interceptor对象,这一部分我们忽略,剩下的Interceptor对象还有如下几个:
1. RetryAndFollowUpInterceptor: 失败重试以及重定向
2. BridgeInterceptor: 用户友好代码和网络友好代码之间的转化。
3. CacheInterceptor: 读取缓存直接返回、更新缓存
4. ConnectInterceptor: 和服务器建立连接
5. CallServerInterceptor: 向服务器发送请求数据、从服务器读取响应数据的
第一个分析RetryAndFollowUpInterceptor这个Interceptor对象。
RetryAndFollowUpInterceptor
作为网络框架,意外不可避免,尤其是外部环境导致的意外,这个时候要有合理的恢复策略,同时在HTTP的世界中,还存在服务端修改了域名,旧的域名要通过重定向访问到新的域名的情况。对于框架来说,异常和重定向都是需要重新请求网络的,就在这个拦截器都给处理了。
interceptor()
@Override public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(request.url()), callStackTrace);
int followUpCount = 0;
Response priorResponse = null;
while (true) {
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response = null;
boolean releaseConnection = true;
try {
response = ((RealInterceptorChain) chain).proceed(request, streamAllocation, null, null);
releaseConnection = false;
} catch (RouteException e) {
// The attempt to connect via a route failed. The request will not have been sent.
if (!recover(e.getLastConnectException(), false, request)) {
throw e.getLastConnectException();
}
releaseConnection = false;
continue;
} catch (IOException e) {
// An attempt to communicate with a server failed. The request may have been sent.
boolean requestSendStarted = !(e instanceof ConnectionShutdownException);
if (!recover(e, requestSendStarted, request)) throw e;
releaseConnection = false;
continue;
} finally {
// We're throwing an unchecked exception. Release any resources.
if (releaseConnection) {
streamAllocation.streamFailed(null);
streamAllocation.release();
}
}
// Attach the prior response if it exists. Such responses never have a body.
if (priorResponse != null) {
response = response.newBuilder()
.priorResponse(priorResponse.newBuilder()
.body(null)
.build())
.build();
}
// 将服务端返回的消息转换为新的Request
// 比如服务端返回301,会在Header头有Location字段告诉你要跳转到哪里。
Request followUp = followUpRequest(response);
if (followUp == null) {
if (!forWebSocket) {
streamAllocation.release();
}
return response;
}
closeQuietly(response.body());
// 不会无限的重定向跟踪,防止环形重定向或者造成攻击
// MAX_FOLLOW_UPS的次数是20
if (++followUpCount > MAX_FOLLOW_UPS) {
streamAllocation.release();
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
}
if (followUp.body() instanceof UnrepeatableRequestBody) {
streamAllocation.release();
throw new HttpRetryException("Cannot retry streamed HTTP body", response.code());
}
if (!sameConnection(response, followUp.url())) {
streamAllocation.release();
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(followUp.url()), callStackTrace);
} else if (streamAllocation.codec() != null) {
throw new IllegalStateException("Closing the body of " + response
+ " didn't close its backing stream. Bad interceptor?");
}
request = followUp;
priorResponse = response;
}
}
首先构造了StreamAllocation对象,该对象将三个实体的关系联系起来了。分别是
- Connections: 物理socket链接到远端服务
- Streams: 逻辑上的HTTP request/response对,在Connections层之上。
- Calls: 逻辑上的流的序列,通常是一个初始请求和接下来的跳转请求。
然后,尝试从服务端获取请求,获取请求之后处理请求,通过followUpRequest()方法,这个方法是这个拦截器处理的核心。如果获取响应失败,则会尝试恢复请求,这个处理内容在recover()方法内,其他的一些错误处理我这里就不解析了。那我们来看一看followUpRequest()方法。
followUpRequest()
/**
* Figures out the HTTP request to make in response to receiving {@code userResponse}. This will
* either add authentication headers, follow redirects or handle a client request timeout. If a
* follow-up is either unnecessary or not applicable, this returns null.
*/
private Request followUpRequest(Response userResponse) throws IOException {
if (userResponse == null) throw new IllegalStateException();
Connection connection = streamAllocation.connection();
Route route = connection != null
? connection.route()
: null;
int responseCode = userResponse.code();
final String method = userResponse.request().method();
switch (responseCode) {
// HTTP Status-Code 407: Proxy Authentication Required.
// 需要代理,则调用创建okhttp对象的时候设置的代理对象
case HTTP_PROXY_AUTH:
Proxy selectedProxy = route != null
? route.proxy()
: client.proxy();
if (selectedProxy.type() != Proxy.Type.HTTP) {
throw new ProtocolException("Received HTTP_PROXY_AUTH (407) code while not using proxy");
}
return client.proxyAuthenticator().authenticate(route, userResponse);
// HTTP Status-Code 401: Unauthorized.
// 需要身份验证,则调用创建okhttp对象的时候设置的验证对象,加入对应的信息
case HTTP_UNAUTHORIZED:
return client.authenticator().authenticate(route, userResponse);
case HTTP_PERM_REDIRECT:
case HTTP_TEMP_REDIRECT:
// "If the 307 or 308 status code is received in response to a request other than GET
// or HEAD, the user agent MUST NOT automatically redirect the request"
if (!method.equals("GET") && !method.equals("HEAD")) {
return null;
}
// fall-through
case HTTP_MULT_CHOICE:
case HTTP_MOVED_PERM:
case HTTP_MOVED_TEMP:
case HTTP_SEE_OTHER:
// Does the client allow redirects?
if (!client.followRedirects()) return null;
// Header 头中读取Location字段
String location = userResponse.header("Location");
if (location == null) return null;
// 通过Location字段的值构造新的请求的url
HttpUrl url = userResponse.request().url().resolve(location);
// Don't follow redirects to unsupported protocols.
if (url == null) return null;
// If configured, don't follow redirects between SSL and non-SSL.
boolean sameScheme = url.scheme().equals(userResponse.request().url().scheme());
if (!sameScheme && !client.followSslRedirects()) return null;
// Most redirects don't include a request body.
Request.Builder requestBuilder = userResponse.request().newBuilder();
if (HttpMethod.permitsRequestBody(method)) {
final boolean maintainBody = HttpMethod.redirectsWithBody(method);
// 除了PROPFIND(WebDAV用的)请求,其他请求都要转为GET请求
if (HttpMethod.redirectsToGet(method)) {
requestBuilder.method("GET", null);
} else {
RequestBody requestBody = maintainBody ? userResponse.request().body() : null;
requestBuilder.method(method, requestBody);
}
if (!maintainBody) {
requestBuilder.removeHeader("Transfer-Encoding");
requestBuilder.removeHeader("Content-Length");
requestBuilder.removeHeader("Content-Type");
}
}
// When redirecting across hosts, drop all authentication headers. This
// is potentially annoying to the application layer since they have no
// way to retain them.
if (!sameConnection(userResponse, url)) {
requestBuilder.removeHeader("Authorization");
}
return requestBuilder.url(url).build();
case HTTP_CLIENT_TIMEOUT:
// 408's are rare in practice, but some servers like HAProxy use this response code. The
// spec says that we may repeat the request without modifications. Modern browsers also
// repeat the request (even non-idempotent ones.)
if (userResponse.request().body() instanceof UnrepeatableRequestBody) {
return null;
}
// 超时返回原始的请求,就代表重新请求
return userResponse.request();
default:
return null;
}
}
主要的解析都在代码中以注释的形式出现了。 到这里,这个Interceptor就解析完毕了,我们来看看文章最开头链上下一个Interceptor:
BridgeInterceptor
作为框架,不可能要求所有使用者都对HTTP协议理解的很深刻。所以,框架需要将HTTP协议中约定的信息加入其中,要让使用者尽可能少的处理HTTP协议的细节,这就是这个Interceptor的任务。
interceptor()
@Override public Response intercept(Chain chain) throws IOException {
Request userRequest = chain.request();
Request.Builder requestBuilder = userRequest.newBuilder();
RequestBody body = userRequest.body();
if (body != null) {
MediaType contentType = body.contentType();
if (contentType != null) {
requestBuilder.header("Content-Type", contentType.toString());
}
// 从这里可以看出,HTTP请求头的Content-Length和Transfer-Encoding是互斥的
long contentLength = body.contentLength();
if (contentLength != -1) {
requestBuilder.header("Content-Length", Long.toString(contentLength));
requestBuilder.removeHeader("Transfer-Encoding");
} else {
requestBuilder.header("Transfer-Encoding", "chunked");
requestBuilder.removeHeader("Content-Length");
}
}
if (userRequest.header("Host") == null) {
requestBuilder.header("Host", hostHeader(userRequest.url(), false));
}
if (userRequest.header("Connection") == null) {
requestBuilder.header("Connection", "Keep-Alive");
}
// If we add an "Accept-Encoding: gzip" header field we're responsible for also decompressing
// the transfer stream.
boolean transparentGzip = false;
// 不指定Accept-Encoding请求头,默认使用gzip,压缩数据
if (userRequest.header("Accept-Encoding") == null) {
transparentGzip = true;
requestBuilder.header("Accept-Encoding", "gzip");
}
List<Cookie> cookies = cookieJar.loadForRequest(userRequest.url());
if (!cookies.isEmpty()) {
requestBuilder.header("Cookie", cookieHeader(cookies));
}
// 用户设置了UA,这里就不能覆盖了,否则使用当前okhttp版本作为UA
if (userRequest.header("User-Agent") == null) {
requestBuilder.header("User-Agent", Version.userAgent());
}
Response networkResponse = chain.proceed(requestBuilder.build());
HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers());
Response.Builder responseBuilder = networkResponse.newBuilder()
.request(userRequest);
if (transparentGzip
&& "gzip".equalsIgnoreCase(networkResponse.header("Content-Encoding"))
&& HttpHeaders.hasBody(networkResponse)) {
// 因为响应式gzip编码,所以需要先解压
GzipSource responseBody = new GzipSource(networkResponse.body().source());
Headers strippedHeaders = networkResponse.headers().newBuilder()
.removeAll("Content-Encoding")
.removeAll("Content-Length")
.build();
responseBuilder.headers(strippedHeaders);
responseBuilder.body(new RealResponseBody(strippedHeaders, Okio.buffer(responseBody)));
}
return responseBuilder.build();
}
这里理解起来很容易,看代码中的注释即可,接下来看下一个Interceptor:
CacheInterceptor
网络请求毕竟是一个缓慢的操作,所以,可以通过缓存来加速,但是,不能所有都缓存,也不能什么情况下都从缓存中拿数据,这里就是处理这个逻辑的地方。
intercept()
@Override public Response intercept(Chain chain) throws IOException {
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
// 根据HTTP的Date|Expires|Last-Modified|ETag|Age头来确定对应的策略
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
if (cache != null) {
cache.trackResponse(strategy);
}
if (cacheCandidate != null && cacheResponse == null) {
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
}
// If we're forbidden from using the network and the cache is insufficient, fail.
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
// If we don't need the network, we're done.
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
Response networkResponse = null;
try {
networkResponse = chain.proceed(networkRequest);
} finally {
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null) {
closeQuietly(cacheCandidate.body());
}
}
// If we have a cache response too, then we're doing a conditional get.
if (cacheResponse != null) {
// HTTP Status-Code 304: Not Modified.
// 存在缓存,服务端还返回这个HTTP状态码
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
if (HttpHeaders.hasBody(response)) {
CacheRequest cacheRequest = maybeCache(response, networkResponse.request(), cache);
response = cacheWritingResponse(cacheRequest, response);
}
return response;
}
这里主要通过CacheStrategy类来管理Cache的储存策略,比如要不要保存Cache,保存Cache的超时时间等等,详细内容看这个类即可。
如果没网,不存在Cache就返回504状态码的响应,否则返回cache响应。
通过网络请求获取响应。响应的状态码304的情况下,还存在缓存,则更新缓存,返回对应的响应。
最后,不存在缓存的情况下去除cacheResponse和networkResponse的body,返回通过请求获取的响应。
接着看下一个Interceptor:
ConnectInterceptor
这个Interceptor的作用就是建立与服务端的连接,为什么将连接服务器和服务器之间的交互分开呢?我觉得因为提供的networkInterceptors对象,这个对象给了框架使用者这样一种能力,在连接到服务器的时候做一些需要的操作(我暂时没遇到这样的需求,所以对这里理解不深,大家有想法的可以在评论里告诉我)
intercept()
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
HttpCodec httpCodec = streamAllocation.newStream(client, doExtensiveHealthChecks);
RealConnection connection = streamAllocation.connection();
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
还记得分析RetryAndFollowUpInterceptor过程中出现的StreamAllocation对象吗?这里又出现,根据前面说的,HttpCodec就是一个Stream,RealConnection就是Connection。那也就意味着,逻辑的HTTP请求响应是HttpCodec负责处理的。
这里就简单分析一下HttpCodec,对它有个具体的认识,到分析下一个Interceptor的时候,才不会那么头疼。
/** Encodes HTTP requests and decodes HTTP responses. */
public interface HttpCodec {
/**
* The timeout to use while discarding a stream of input data. Since this is used for connection
* reuse, this timeout should be significantly less than the time it takes to establish a new
* connection.
*/
int DISCARD_STREAM_TIMEOUT_MILLIS = 100;
/** Returns an output stream where the request body can be streamed. */
Sink createRequestBody(Request request, long contentLength);
/** This should update the HTTP engine's sentRequestMillis field. */
void writeRequestHeaders(Request request) throws IOException;
/** Flush the request to the underlying socket. */
void finishRequest() throws IOException;
/** Read and return response headers. */
Response.Builder readResponseHeaders() throws IOException;
/** Returns a stream that reads the response body. */
ResponseBody openResponseBody(Response response) throws IOException;
/**
* Cancel this stream. Resources held by this stream will be cleaned up, though not synchronously.
* That may happen later by the connection pool thread.
*/
void cancel();
}
可以看到HttpCodec是一个接口,为什么是一个接口呢?因为HTTP协议的兼容性问题,HTTP现在已经存在两种实现了,分为HTTP1和HTTP2,HTTP协议的不同,当然,进行这些操作的实现方式也不一样,所以,通过接口隔离具体协议实现方式的不同。当然,具体的实现在streamAllocation.newStream()这里,通过连接到服务器,服务器会返回接受的协议,发现服务端接受”h2”,则使用Http2Codec,否则使用Http1Codec
好了,终于到了最后一个Interceptor:
CallServerInterceptor
前面的Interceptor做了这么多铺垫,就等着最后一个Interceptor完成最后一步,向服务端发送请求,从服务端获取请求。
intercept()
@Override public Response intercept(Chain chain) throws IOException {
HttpCodec httpCodec = ((RealInterceptorChain) chain).httpStream();
StreamAllocation streamAllocation = ((RealInterceptorChain) chain).streamAllocation();
Request request = chain.request();
long sentRequestMillis = System.currentTimeMillis();
// 发送request header
httpCodec.writeRequestHeaders(request);
if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null) {
// 发送request body
Sink requestBodyOut = httpCodec.createRequestBody(request, request.body().contentLength());
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
request.body().writeTo(bufferedRequestBody);
bufferedRequestBody.close();
}
// 完成request
httpCodec.finishRequest();
// 读取response header
Response response = httpCodec.readResponseHeaders()
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
int code = response.code();
if (forWebSocket && code == 101) {
// Connection is upgrading, but we need to ensure interceptors see a non-null response body.
response = response.newBuilder()
.body(Util.EMPTY_RESPONSE)
.build();
} else {
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
}
if ("close".equalsIgnoreCase(response.request().header("Connection"))
|| "close".equalsIgnoreCase(response.header("Connection"))) {
streamAllocation.noNewStreams();
}
if ((code == 204 || code == 205) && response.body().contentLength() > 0) {
throw new ProtocolException(
"HTTP " + code + " had non-zero Content-Length: " + response.body().contentLength());
}
return response;
}
主要流程是: 1. 发送request header 2. 存在request body,发送给服务端 3. 完成request 4. 读取服务端response header,生成Response对象 5. 存在response body,则将body添加到上一步生成的Response对象里
好了,到这里我们就把Interceptor链给分析完毕了。然后Response对象就一层层的返回到之前的Interceptors里了。如果前面的Interceptor关心Response,就重新进行这样的链式处理,否则就返回给我们调用网络请求的地方,这样我们就拿到了需要的Response对象。
通过我们的分析,可以看出,这个责任链把功能分层分的淋漓尽致,需要什么功能,加一个专门的Interceptor即可,了解到了这样一种简洁干净的设计,以后写代码的时候就可以借鉴一下。